This is a simple guide to run DeepSeek locally on your home computer. It assumes you have some background with Large Language Models (LLM), or can follow simple directions.
This guide uses the following software (on a Windows PC):
My hardware is a threadripper PC, 128GB RAM, two RTX 3090 + one RTX 2080 super (total ~56GB vRAM)
– Ollama (runs the model)
– Docker (to run Open WebUI)
– Open WebUI (that handles the web-based user interface)
This guide can be replicated on any PC with at least 8gb vRAM (must have a graphics card)
1. Setup software
Setup Ollama
Install Ollama onto your system (Ollama is a backend that runs LLMs, but does not include a Graphical User Interface (GUI, basically the web page you interact with)
Install via the following link:
https://ollama.com/download/windows
Once complete, test it is working:
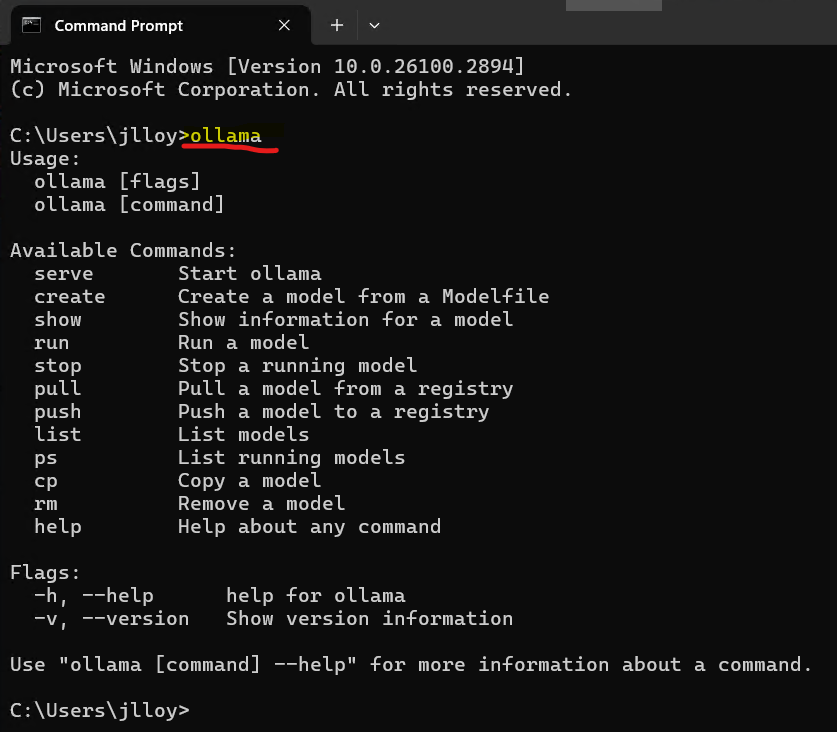
- Open a command prompt (type “cmd” into the search bar to open Command Prompt)
- In command prompt, type “ollama” and press enter
- You should see a list of commands pop up, this indicates Ollama is working. You can close the command prompt window, as Ollama runs in the background of your computer:
- If the response is “‘ollama’ is not recognized as an internal or external command,operable program or batch file.” then your installation has failed, try again.
This step is done when: you can open Ollama from your command prompt
Setup Docker
If you don’t already have Docker, setup from the following directions (no modifications needed, run as is)
https://docs.docker.com/desktop/setup/install/windows-install
This step is done when: you can open Docker on your computer:
Setup OpenWebUI
OpenWeb UI is just an interface that allows you to interact with Ollama. There are multiple interfaces.
Follow the directions from the quick start site:
https://docs.openwebui.com/getting-started/quick-start
- At the time of this writing, all that was needed was to run the following (note, this is because I have a Nvidia GPU):
docker pull ghcr.io/open-webui/open-webui:maindocker run -d -p 3000:8080 --gpus all -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:cuda- This second command only works for people with Nvidia GPUs (CUDA is only on Nvidia GPUs)
- Other directions are available at the link above
Once complete, you should see a new container in your Docker program:
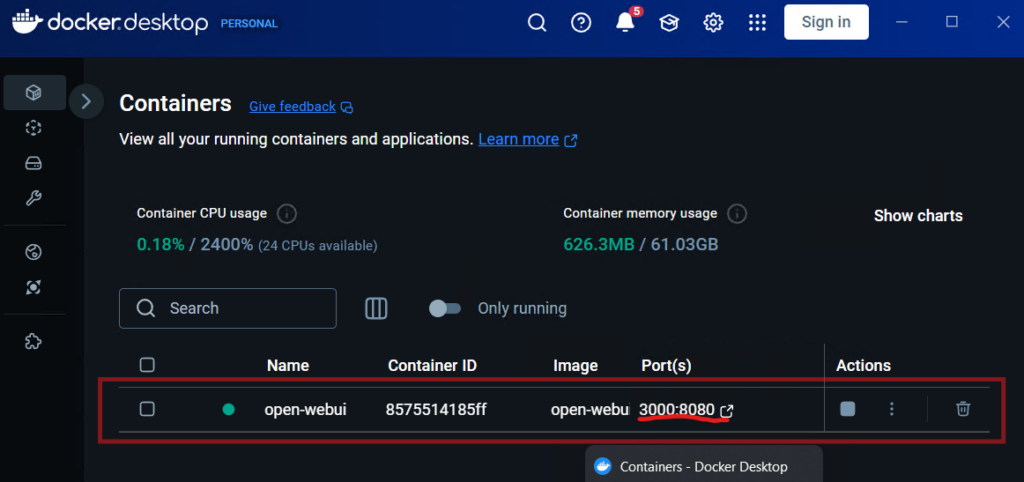
Click on the Port to launch the Web User Interface.
- Once it comes up, create a login
- This is running locally, so this is your method to authenticate yourself. It does not create an online account.
- Here’s the documentation from Open WebUI on creating an account: Link
This step is done when: you can open the GUI (via clicking on the “Port(s)” in the Docker Container, and have gotten into Open WebUI
Note: you should not have a model loaded yet
2. Determine what version of deepseek to download
There are different versions of deepseek (and other LLM models). The two elements are: Parameters (more is better), and Quantization (higher is better), however, in the end you’ll be limited to whatever will fit on your graphics card (your vRAM).
Basics on Parameters and Quantization
- Parameters (usually 7 billion, 14 billion, 32 billion, etc…)
- This is how many parameters the model uses
- Typically, if you are running uncompressed models, each billion parameters takes about 1GB vRAM
- So if you have 8GB vRAM, the full model with 16bit quantization you can probably run around 7B parameter models
- Bigger parameters = bigger LLM models (you’ll be limited to what will fit into your vRAM)
- So a 7b version of a model might be 7GB in size, where as a 40B parameter model may be around 40GB in size
- Bigger parameters = ‘smarter’ model
- A 7b version of a model may seem dumb, whereas the 40b version of a model may seem almost human, due to the depth of knowledge it has
- Quantization (compression, 16, 8, 6 or 4 typically)
- Think of this as compression, there is some trade of between quality and size
- Lower values = smaller models size
- 16 bits: 1b parameters = ~ 1GB model size
- 4 bits: 1b parameters = ~0.6gb model size
- If you want additional details, here’s a full paper on the topic, but for our purposes know:
- More bits (16, 8, 6) = smarter model, full model size
- Medium bits (5, 4) = good enough model, medium size and fast
- Low bits (2, 3) = small model, may not be coherent/smart, very small
Fortunately, Ollama makes finding models that will work easy. Ollama has models ready for download that all meet, what I would consider, good levels of compression while still retaining coherentness.
First: you need to know how much vRAM your computer has (how much RAM is on your graphics card)
How to determine how much vRAM your computer has
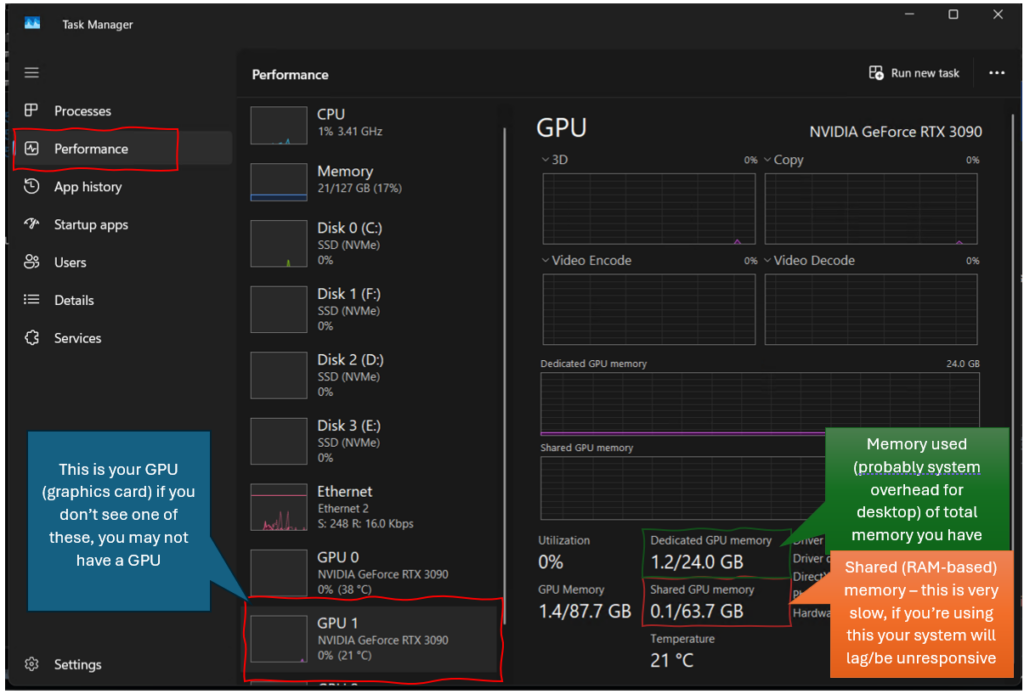
- On your computer (Windows) press the keys Ctrl + Alt + Delete to bring up the Task Manager.
- In task manager, open
- In task manager, click on Performance
- Click on your GPU
- The amount of vRAM you have is your Dedicated Video Memory
- The amount used is what the system is currently using to run the system
- The total is how much you have overall
- Typically, your avaliable vRAM is the difference between these two
- So if total = 24GB, used = 1.2 GB, then vRAM available = 24-1.2 = 22.8 GB
- Note: if you have multiple video cards (like me) you can add the vRAM together to get your total.
Second: find the version of Deepseek that fits in your vRAM
Ollama models are ready for download
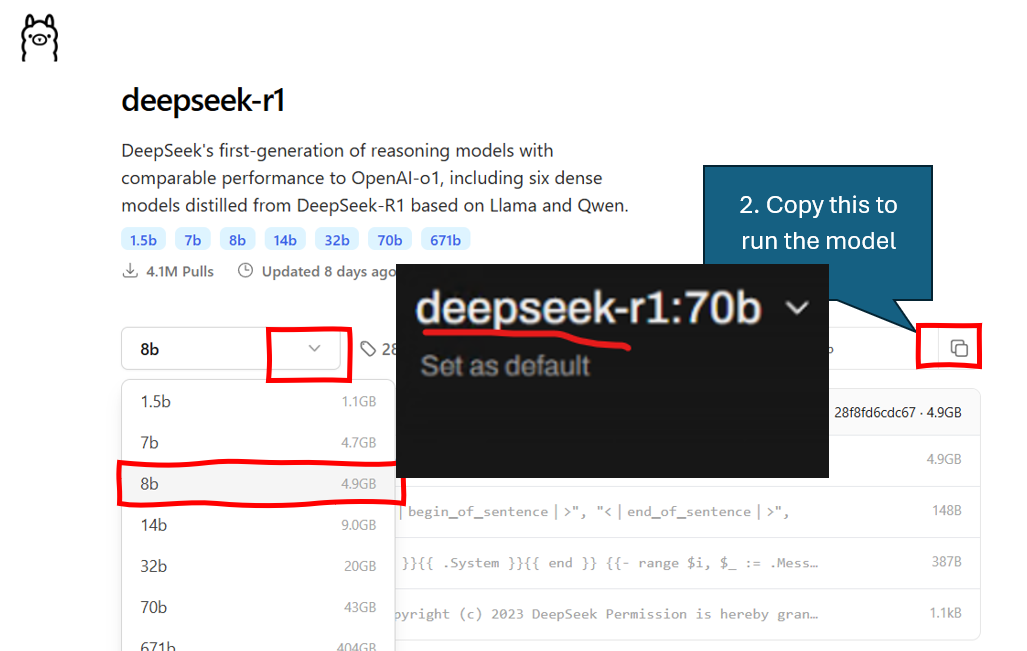
- Go to the Ollama model page for deepseek
- Click the drop down to select a model version that will fit in your vRAM
- Note, I typically try to ensure the model only takes up no more than 70% of my available vRAM.
- Example, you have a RTX 4060 with 8GB vRAM, your system uses 1GB of this so your free vRAM is ~ 7 GB. The available models under this would be either the 7B version, or the 8B version.
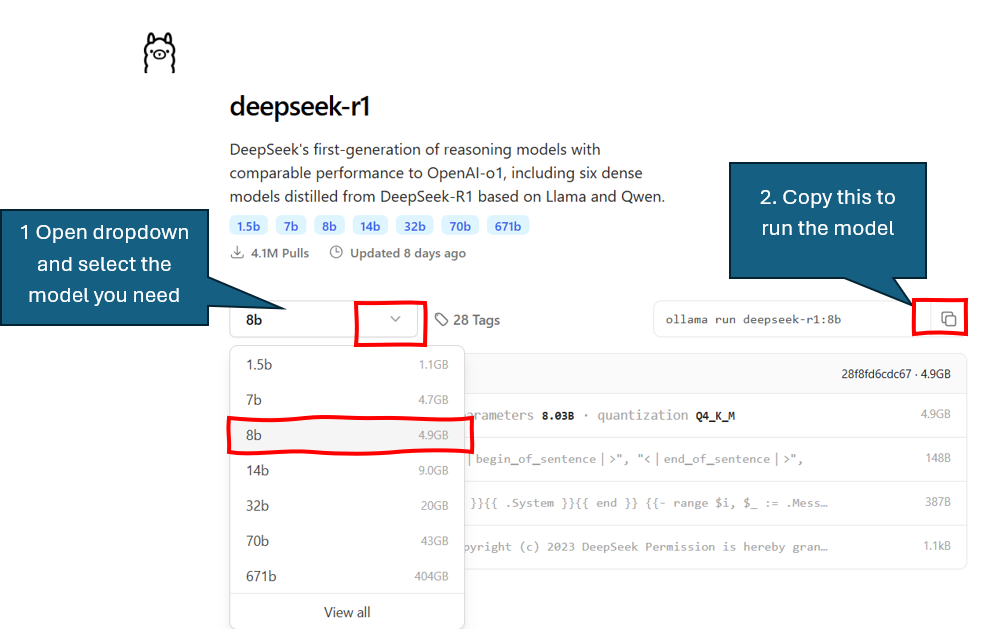
Once selected, click the “Copy” button to copy the model details to run.
3. Download deepseek
Open the Command Prompt (type “CMD” into the search bar and the Command Prompt should show up, click on “Command Prompt” to open).
Paste in the run command (the text copied from Ollama’s site for the model you want), then press “enter”. The model will download and start.

Ollama will download the model and start it.
Once the model is downloaded you can close the command prompt.
4. Use DeepSeek
Open your Open Web UI, via Docker Desktop.
Note: you may need to refresh the webpage (GUI) to get DeepSeek to show up. If you have significant issues, stop your Docker container (via the Stop button next to the port in Docker Desktop) and restart (after stopping the button will look like a “Play” button, click that to restart, then click the web address to load).
Once into Open WebUI, use the dropdown to select DeepSeek, and you can now use your model!

Victory: DeepSeek is now running on your computer, and you should be able to use it locally.
The DeepSeek model will “think” before responding.
My system takes about 30 seconds to generate a response.


Leave a Reply